Learning how to do logistic regression in Excel can add a powerful predictive tool to your toolbox. With artificial intelligence and machine learning dominating the technology main stage, logistic regression and other predictive algorithms like linear regression have begun to permeate mainstream business vernacular. Because logistic regression can predict the likelihood of an event, it has a wide range of business applications, from fraud detection to sales revenue forecasting.
Predictive algorithms have long been accessible in spreadsheet applications like Excel, though they lack the compute, storage, and processing capabilities of the cloud and big data infrastructure. We’ll show you how to use them to do a logistic regression in Excel in six steps, giving you the ability to make predictions from your data right on your desktop.
Logistic regression is a statistical analysis technique for transforming a linear function’s output into a probability value. Unlike linear regression, which predicts continuous outcomes, logistic regression predicts the probability of an event occurring by using a logistic function to predict the probability of a binary outcome. These types of predictions that categorize based on two outcomes are called binary classification tasks.
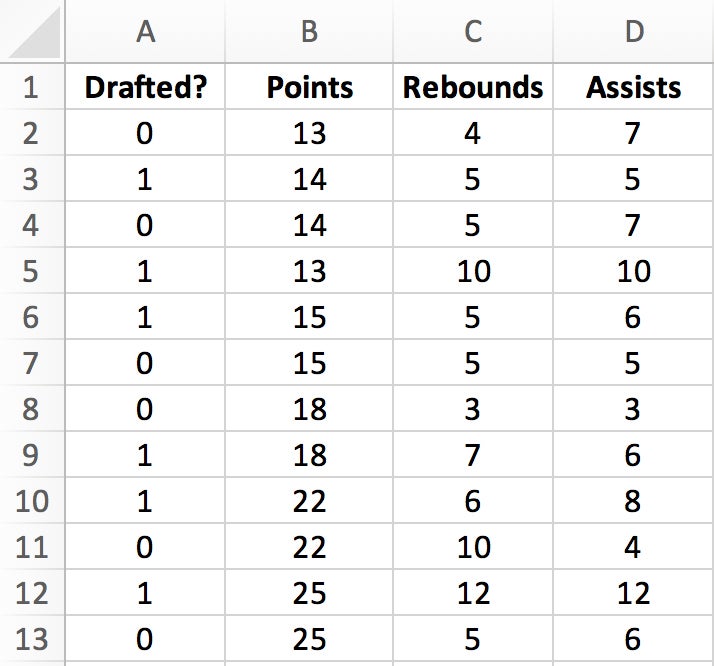
For our example, you’ll perform a logistic regression in Excel to determine whether a college basketball player is likely to get drafted into the NBA. Your dataset includes basic performance metrics from the previous season:
Because logistic regression is a binary classification problem, the target prediction is a simple binary classification value of the likelihood of being drafted:
The first step is to create the tabular structure in Excel for holding your dataset and performing calculations and transformations.
| Drafted? | Points | Rebounds | Assists |
|---|---|---|---|
| 0 | 13 | 4 | 7 |
| 1 | 14 | 5 | 5 |
| 0 | 14 | 5 | 7 |
| 1 | 13 | 10 | 10 |
| 1 | 15 | 5 | 6 |
| 0 | 15 | 5 | 5 |
| 0 | 18 | 3 | 3 |
| 1 | 18 | 7 | 6 |
| 1 | 22 | 6 | 8 |
| 0 | 22 | 10 | 4 |
| 1 | 25 | 12 | 12 |
| 0 | 25 | 5 | 6 |
Once you’ve inserted the dataset, your spreadsheet should look like Figure 1.
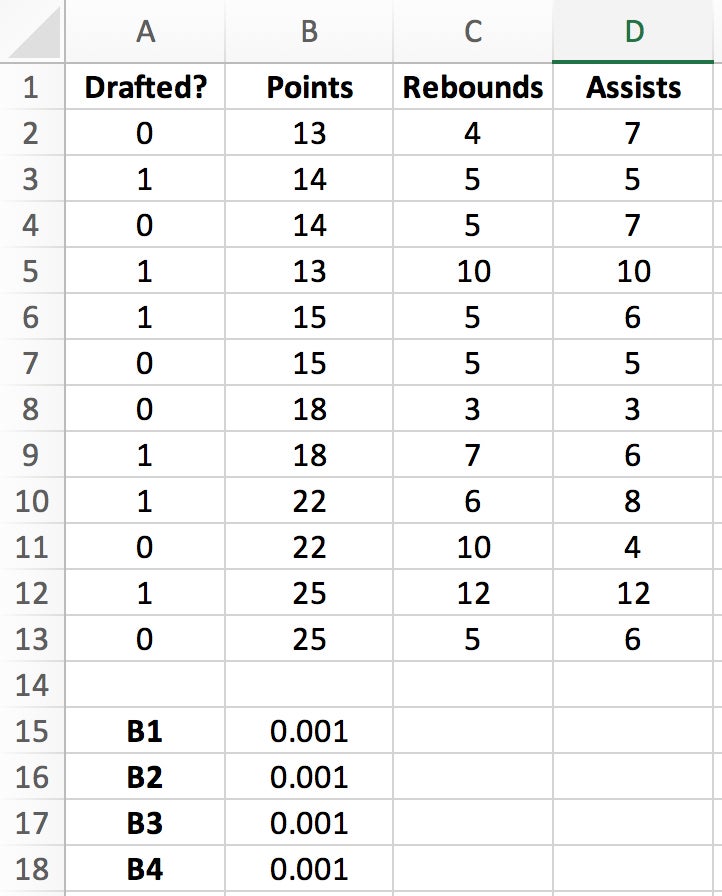
Create a corresponding cell for each of your columnar variables—Points, Rebounds, Assists—to hold your regression coefficients.
Next we’ll create columns for optimizing the regression coefficients. We’ll need these to calculate predictions in later steps, but for now we’ll focus on populating four new columns:
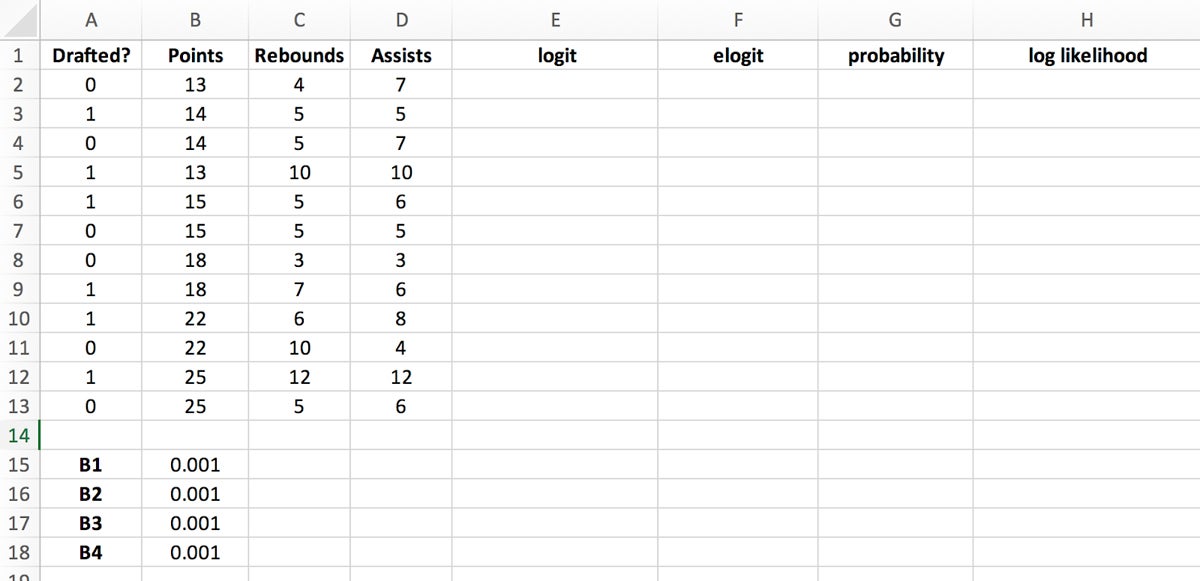

In Excel, you can use the formula $B$15+$B$16*B2+$B$17*C2+$B$18*D2 to easily derive the logit value. Place this formula into the first logit cell and drag the bottom right corner of the highlighted cell to the last logit cell to populate the column.
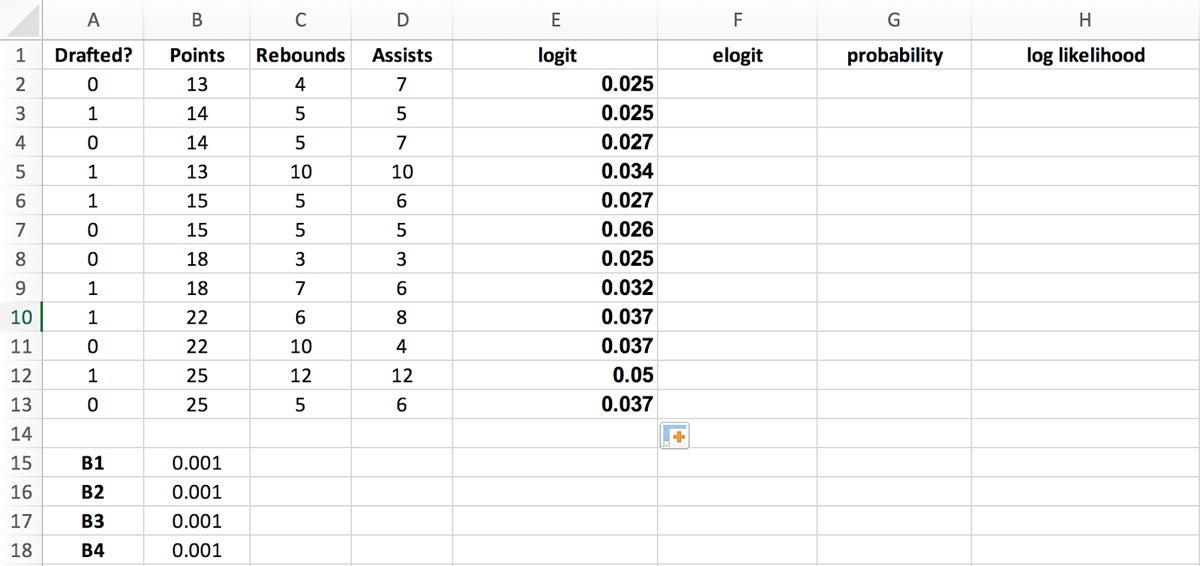
You can use Excel’s EXP function to get this value. Place the formula =EXP(E2) into the first elogit cell and drag the bottom right corner of the highlighted cell to the last elogit cell to populate the column.
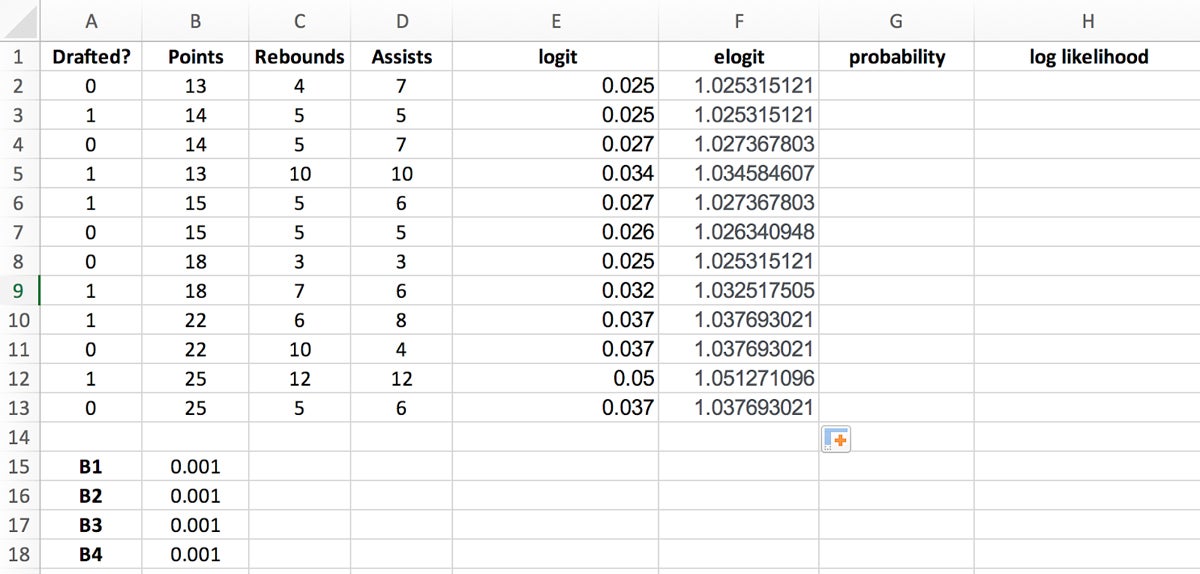

In our example:
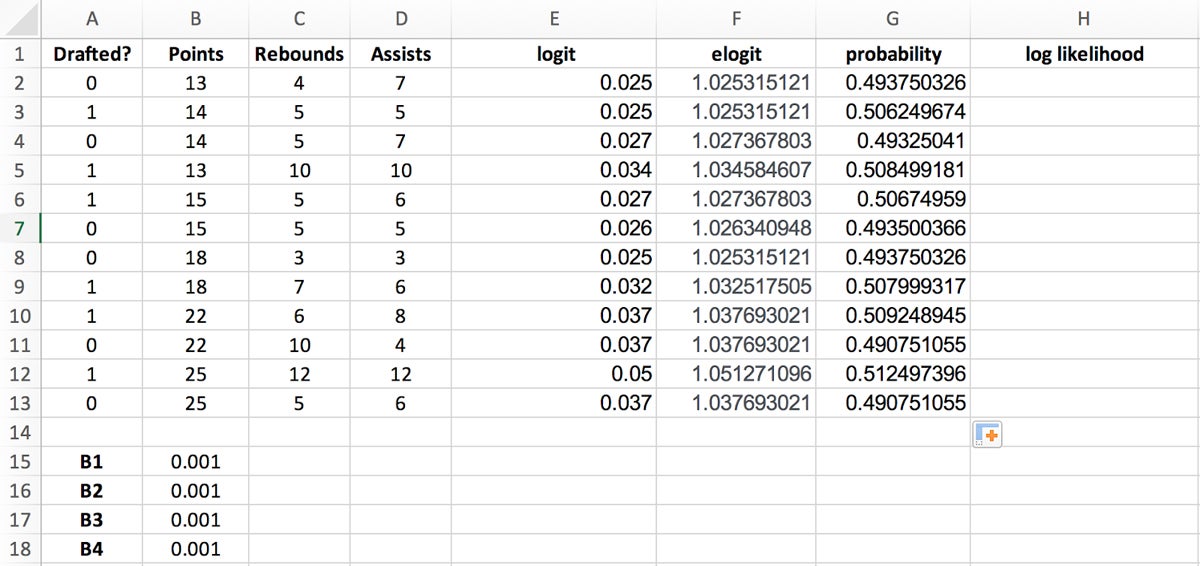
In Excel, you can use the formula =IF(A2=1, F2/(1+F2), 1-(F2/(1+F2))) to derive the probability values by placing this formula into the first probability cell and dragging the bottom right corner of the highlighted cell to the last probability cell to populate the column.
Your spreadsheet should now look like Figure 6.
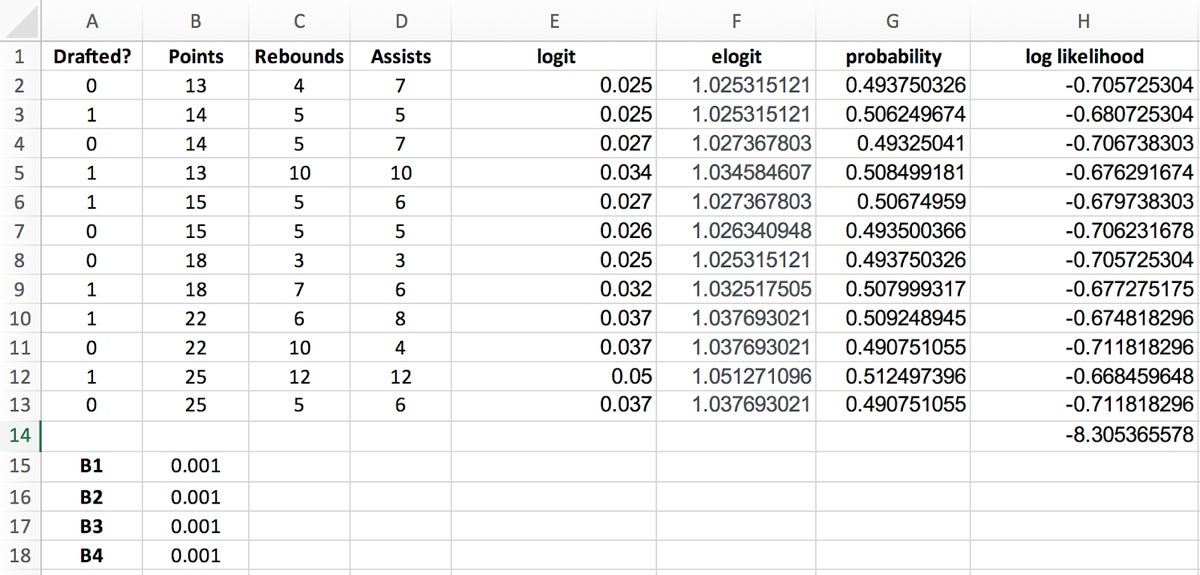
Because adding logarithms is computationally more efficient than multiplying probabilities directly, you’ll need to calculate the log likelihood values to simplify your calculations and make them more practical.
Log likelihood values are calculated by using the following formula:
Log likelihood = LN(probability)
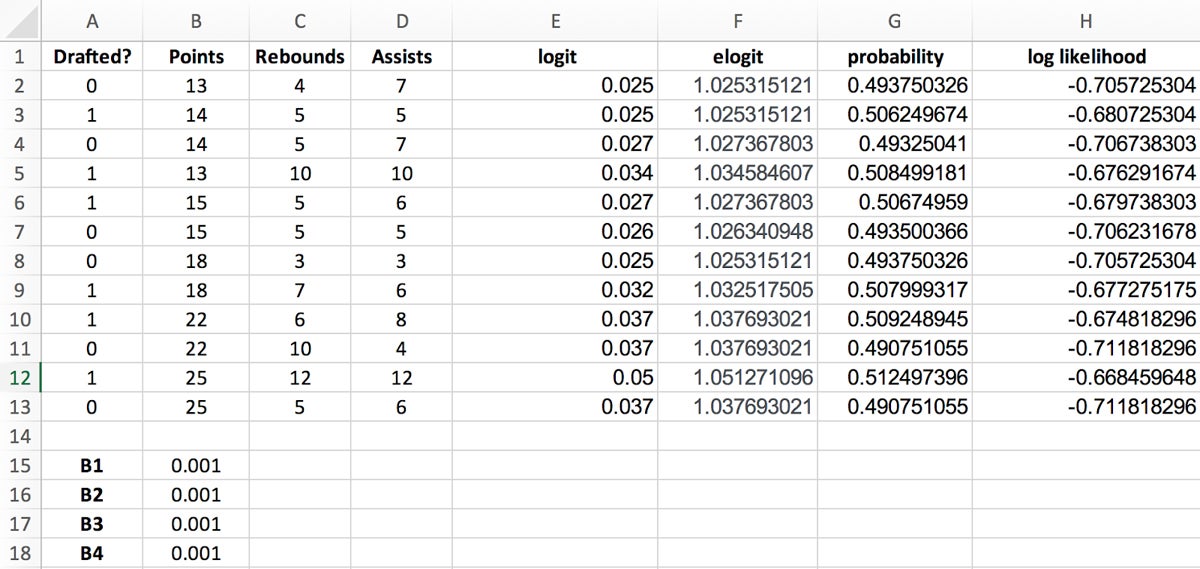
Your spreadsheet should now look like the example in Figure 8.
The last step involves using Excel’s Solver add-in to automatically calculate the regression coefficient estimates.
After Solver finishes automatically calculating your regression coefficient estimates, your spreadsheet should look like Figure 10.

The current regression coefficients default to determining the probability of a non-draft:
Draft? = 0
To get the probability of being drafted (Draft? = 1), simply reverse the regression coefficients signs—for example, reverse the -4.643753 in the p(x=0) column for a positive 4.643753 value in the p(x=1) column.

Now that you have your regression coefficient estimates, you can plug them into the probability equation to find out whether a new player will get drafted. For this example, let’s say the new player averages 15 points per game, 4 rebounds per game, and 6 assists per game. Again, the formula for calculating the probability of being drafted is:

In this example, the formula would look like the following:

Evaluating this equation yields 0.66, or a 66 percent probability this new player will get drafted.
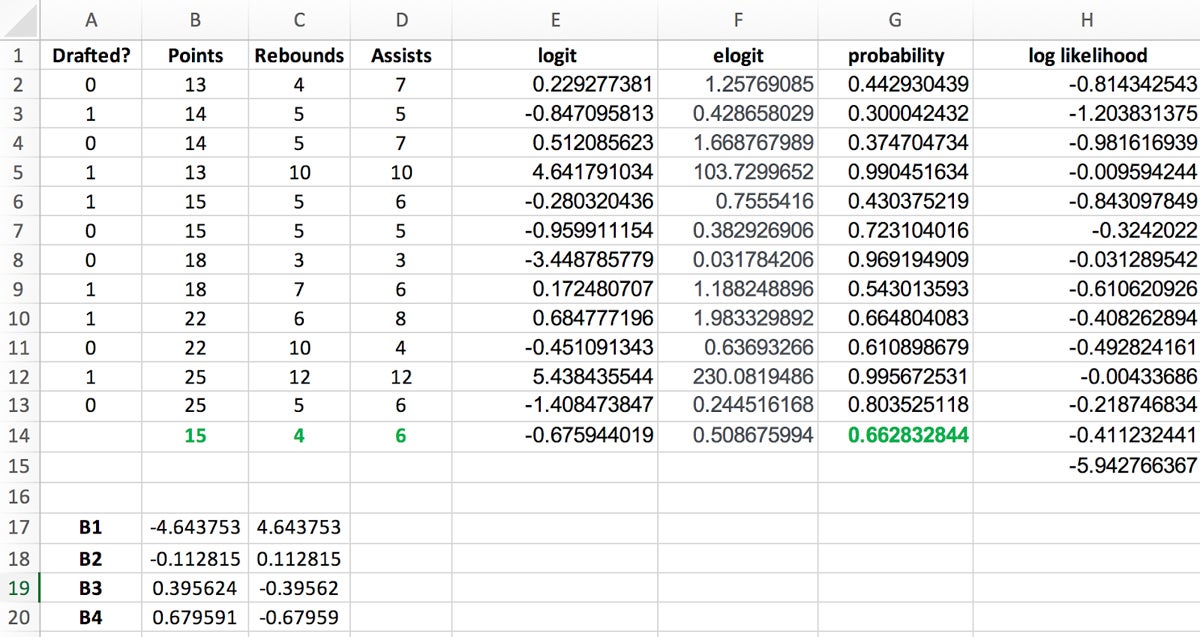
As you can see, the probability of the new player being drafted is also 66 percent, which lines up with the previous manual calculation.
Logistic regression involves predicting the probability of a binary event occurring—for example, success/failure, yes/no, churn/no churn). By definition, probability is a measure of the likelihood of an event occurring, ranging from 0 (impossible) to 1 (certain).
Odds, on the other hand, express the likelihood of success compared to the likelihood of failure. For example, if the probability of success is 0.8, the odds of success are 0.8 / (1 – 0.8) = 4. This means there are four times as many favorable outcomes as unfavorable ones.
Log odds ratio is a calculation method for transforming these odds into a more workable range of values. Specifically, the logistic regression model uses the sigmoid function—denoted as σ(z)—to calculate the log odds ratio, or the logarithm of the odds of success. Mathematically, log odds ratio is represented as:

In this formula, p is the th. By taking the logarithm of the probability’s value, you can map the odds from a scale of 0 to positive infinity, down to a range that extends from negative infinity to positive infinity. In other words, the log odds ratio measures the likelihood of an event happening in one group compared to another, with positive values indicating a higher likelihood in the first group and negative values indicating a higher likelihood in the second group.
When plotted out on a graph, the output of a logistic regression takes on the shape of a sigmoid (S-shaped) curve.
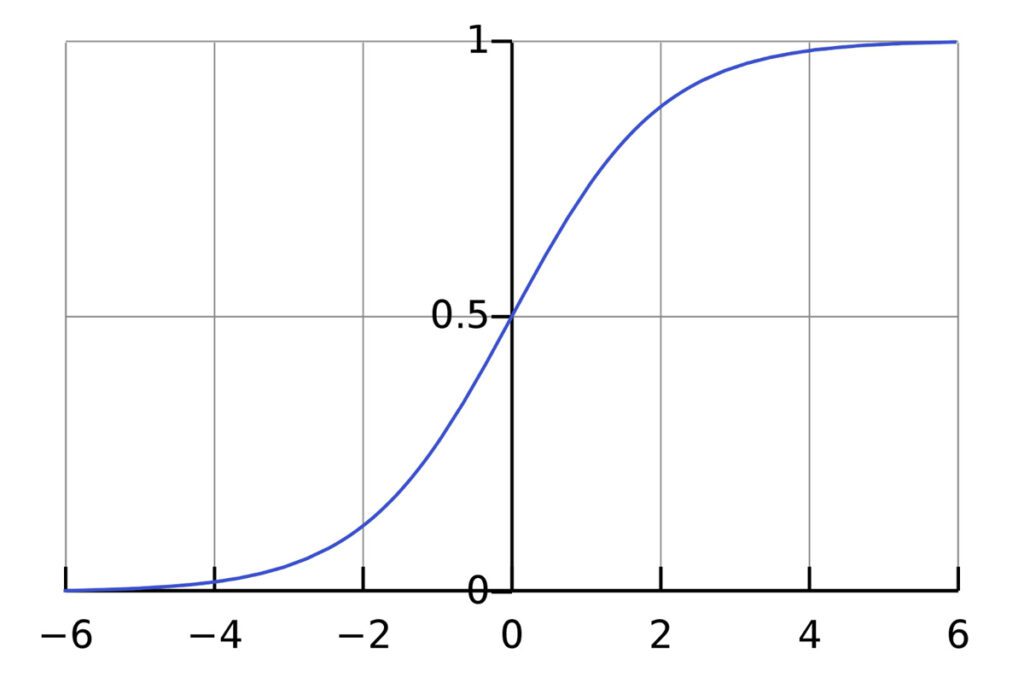
A logistic regression calculates the log odds ratio for each independent variable. As mentioned earlier, when you see a positive coefficient, it means that as the associated independent variable increases, the log odds of the event increase; subsequently, the probability of the event occurring goes up. Conversely, a negative coefficient suggests that as the variable increases, the log odds (and probability) of the event decrease. By mapping the resulting value to the range—0 or 1]—you can make predictions based on calculating probabilities.
Linear regression is used for predicting continuous outcomes, while logistic regression is used for predicting binary outcomes (i.e., the dependent variable is categorical with two possible outcomes).
The odds ratio represents the factor by which the odds of the event increase (or decrease) for a one-unit change in the independent variable. If the odds ratio is greater than one, it suggests an increase in the odds of the event. If it’s less than one, it indicates a decrease.
No, logistic regression is specifically designed for binary classification problems where the dependent variable has only two categories.
Multicollinearity, or scenarios where independent variables are highly correlated, can impact the stability and interpretability of a logistic regression model. Excel’s Data Analysis ToolPak provides a Variance Inflation Factor (VIF) option, which can help identify multicollinearity.
If your model doesn’t perform as expected, you can experiment with different sets of independent variables, address multicollinearity, and explore data transformations.
Whether you’re predicting customer churn, analyzing marketing campaigns, or assessing operational risk factors, logistic regression provides a robust yet elegant framework for predictive modeling and data-driven optimization. The powerful, widely utilized statistical method is a go-to for binary classification problems and is renowned for its interpretability and flexibility in handling various data types; these attributes and more make it a frequently used tool in the data scientist and professional’s statistical toolbox.
If you’re interested in statistical analysis using Excel, learn how to use the spreadsheet tool for Linear Regressions or Monte Carlo Simulations.

Datamation is the leading industry resource for B2B data professionals and technology buyers. Datamation's focus is on providing insight into the latest trends and innovation in AI, data security, big data, and more, along with in-depth product recommendations and comparisons. More than 1.7M users gain insight and guidance from Datamation every year.
Advertise with TechnologyAdvice on Datamation and our other data and technology-focused platforms.
Advertise with Us







Property of TechnologyAdvice.
© 2025 TechnologyAdvice. All Rights Reserved
Advertiser Disclosure: Some of the products that appear on this
site are from companies from which TechnologyAdvice receives
compensation. This compensation may impact how and where products
appear on this site including, for example, the order in which
they appear. TechnologyAdvice does not include all companies
or all types of products available in the marketplace.