Sentiment analysis, also known as opinion mining, is the process of using computational techniques to extract subjective information from textual data
As technology advances, the methods used to gather & measure data will become more streamlined. Learn about data collection trends for business now:

Discover the latest data classification trends shaping industries. What strategies define the future of data protection? Uncover insights now

These are our observations of the data management market today and our predictions for the future of data management.

Part tech implementation, part culture change, digital transformation completely changes the value your business brings to its customers. Learn how.

Digital transformation is the process of transferring tasks and tools into the digital world to completely reinvent business procedures and customer

Is multi-tenant architecture right for you? Learn about its advantages in our comprehensive guide!

Seeking data analytics tools to transform your business? Explore 10 strategic picks for advantage in 2024.

Want to see data come to life? Explore data visualization examples that turn abstract numbers into visual stories.

Explore our guide on Data Management. Learn about systems, processes, and tools for managing data effectively. Learn more!

Curious about how to run a Monte Carlo Simulation in Excel? Let our step-by-step guide help you unlock analytic insights today.
Wondering what structured data is all about? Discover its power in our latest deep dive.

Curious about data virtualization benefits? Learn how it transforms data access and boosts efficiency in our latest article.

What is data analysis? Real-world examples and insights into the art of extracting knowledge from data.

What is qualitative data, and why does it matter? Explore its essential characteristics and real-world examples so you can confidently apply it.

Quantitative Data is data that can be measured numerically. Learn more about the types of quantitative data & how it is used.

Raw data is unprocessed data that has not been organized or analyzed. Learn about raw data, its definition, examples, and processing steps.

Data analytics is an ever-evolving field. Discover the top 7 data analytics trends to watch, from AI-driven analytics to cloud-based solutions.

Deciding on the best AI certification courses to take? Our 2024 guide details the 9 top courses you need!

Considering RPA companies for smarter solutions? Check out 2024's top 9 innovators in business technology today!

Is AI in cybersecurity our future defense? Discover how it reshapes threat detection and security strategies.

Curious about Coursera machine learning for 2024? Gain cutting-edge skills & certification with comprehensive courses.

Interested in AI-powered data classification? Elevate your data management with cutting-edge technology!

Eager to learn about the top 100 AI companies of 2024? Learn about the AI trendsetters of the future.

Which cloud computing companies offer superior services? See our list of 2025's top cloud providers.

Discover the top managed service providers (MSPs) for 2025. Learn about MSPs and their services and find the best one for your needs.
Want to see data come to life? Explore data visualization examples that turn abstract numbers into visual stories.
Deciding on the best AI certification courses to take? Our 2024 guide details the 9 top courses you need!

Interested in cloud based project management software? Optimize workflow with elite software of 2024.

Discover the top software-as-a-service (SaaS) companies. Learn about the latest trends in SaaS and the most successful SaaS companies.
Seeking data analytics tools to transform your business? Explore 10 strategic picks for advantage in 2024.
Want to see data come to life? Explore data visualization examples that turn abstract numbers into visual stories.
Interested in cloud based project management software? Optimize workflow with elite software of 2024.

Wondering how HubSpot CRM stacks up against Salesforce? Read the head-to-head comparison of 2024.

Eager to optimize your data science toolkit? Discover the essentials for 2024.

Curious about data analyst companies? Unveil the 7 best places to advance your career in 2024.

What drives IoT protocols and standards? Uncover the answers in our guide, spotlighting the 12 most influential protocols in the IoT domain.

This article provides the latest trends on the Internet of Things (IoT). Discover the future of IoT.

Low-Code/No-Code (LC/NC) platforms are revolutionizing the software development industry. Today, anyone can use them to create their own app, tool, or

Internet of Things (IoT) devices are transforming business. Explore the top 85 IoT devices & those who are investing in the future of IoT.

What's the state of the wireless networking market, including its features, benefits, use cases, and providers?

How are wireless networking technologies being used by companies in different industries?

Interested in the best open source software? Read our 2024 list for innovative data management solutions.

Exploring open source companies for 2024? Discover the leading firms championing open-source solutions.

Looking for CRM open source software for 2024? Reviewing the 10 best solutions for data management.

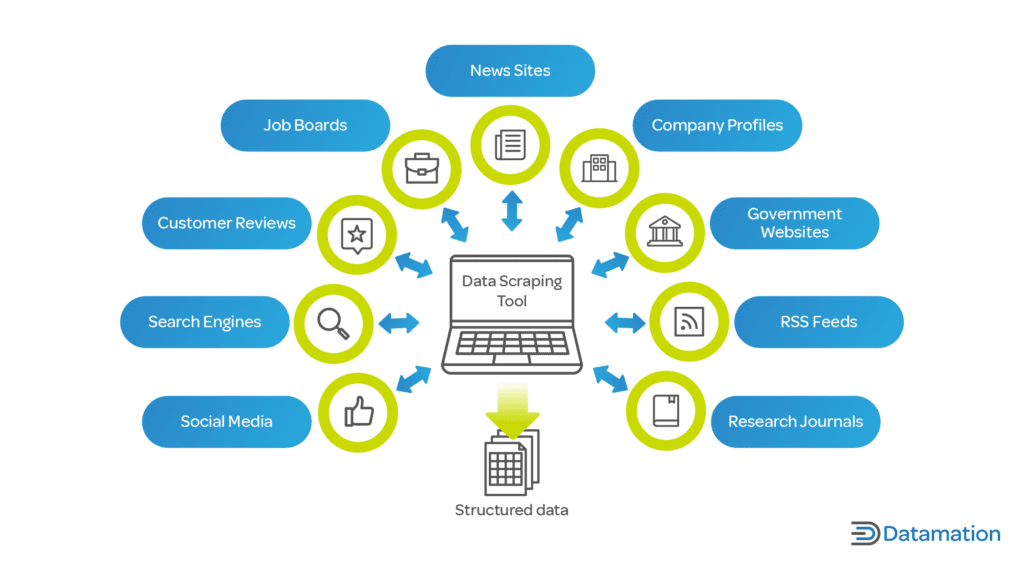
Data Scraping is a process of collecting data from websites & other sources for further processing. Learn about the definition, process & how to use it.

Open source software is a type of software that allows anyone to view the code, and then use the code to contribute to or create other projects. Some This list of leading open source software sites is an ultimate resource for open source software users.
Where does Dell Technologies Enterprise SONiC Distribution stand in the network operating system (NOS) market, including its features & reviews?
Is AI in cybersecurity our future defense? Discover how it reshapes threat detection and security strategies.

Wondering what is cybersecurity? Get a comprehensive overview, expert practices, and insights into cyber threats.

Questioning how to secure a network? Explore 9 key steps for securing your network and safeguarding sensitive data.

Is your data security software ready for 2024? Explore the 7 best solutions now.

Exploring cybersecurity certifications? Uncover the top 11 certifications that employers truly value in IT security.

Discover how to secure your network with an nmap vulnerability scan. Explore the easy, step-by-step process now.

Looking for storage certifications? Learn about the 10 top certifications for data professionals in 2024.

Data compression is a process used to reduce the amount of data sent over a network. Learn about the algorithms used to compress data and how it works.

A data pipeline is a set of processes that move data from one system to another. Learn how data pipelines can help you manage and analyze data efficiently.

Data center certifications are essential for success in the industry. Here are the top 10 certifications to consider to ensure you are ahead of the curve.

Learn the definition of a data lakehouse, the benefits of using one, and the features that make it an essential part of a modern data architecture.

Databases are undergoing massive change as they transition from on-prem to the cloud. Find out what the main trends are in the database space.
- Trends Link to What Is Sentiment Analysis? Essential Guide What Is Sentiment Analysis? Essential Guide
Sentiment analysis, also known as opinion mining, is the process of using computational techniques to extract subjective information from textual data
Link to 11 Top Data Collection Trends Emerging In 202411 Top Data Collection Trends Emerging In 2024As technology advances, the methods used to gather & measure data will become more streamlined. Learn about data collection trends for business now:
Link to 6 Top Data Classification Trends 6 Top Data Classification TrendsDiscover the latest data classification trends shaping industries. What strategies define the future of data protection? Uncover insights now
Link to 7 Data Management Trends: The Future of Data Management 7 Data Management Trends: The Future of Data ManagementThese are our observations of the data management market today and our predictions for the future of data management.
Link to What is Digital Transformation? What is Digital Transformation?Part tech implementation, part culture change, digital transformation completely changes the value your business brings to its customers. Learn how.
Link to Top 7 Digital Transformation Companies Top 7 Digital Transformation CompaniesDigital transformation is the process of transferring tasks and tools into the digital world to completely reinvent business procedures and customer
- Big Data Link to Exploring Multi-Tenant Architecture: A Comprehensive Guide Exploring Multi-Tenant Architecture: A Comprehensive Guide
Is multi-tenant architecture right for you? Learn about its advantages in our comprehensive guide!
Link to 8 Best Data Analytics Tools: Gain Data-Driven Advantage 8 Best Data Analytics Tools: Gain Data-Driven AdvantageSeeking data analytics tools to transform your business? Explore 10 strategic picks for advantage in 2024.
Link to Common Data Visualization Examples: Transform Numbers into Narratives Common Data Visualization Examples: Transform Numbers into NarrativesWant to see data come to life? Explore data visualization examples that turn abstract numbers into visual stories.
Link to What is Data Management? A Guide to Systems, Processes, and Tools What is Data Management? A Guide to Systems, Processes, and ToolsExplore our guide on Data Management. Learn about systems, processes, and tools for managing data effectively. Learn more!
Link to How to Run a Monte Carlo Simulation in Excel: 5 Key Steps How to Run a Monte Carlo Simulation in Excel: 5 Key StepsCurious about how to run a Monte Carlo Simulation in Excel? Let our step-by-step guide help you unlock analytic insights today.
Link to Mastering Structured Data: From Basics to Real-World Applications Mastering Structured Data: From Basics to Real-World ApplicationsWondering what structured data is all about? Discover its power in our latest deep dive.
- Data Center Link to 4 Data Virtualization Benefits: Redefining Data Accessibility 4 Data Virtualization Benefits: Redefining Data Accessibility
Curious about data virtualization benefits? Learn how it transforms data access and boosts efficiency in our latest article.
Link to What Is Data Analysis? Ultimate Guide (+ Real-World Examples) What Is Data Analysis? Ultimate Guide (+ Real-World Examples)What is data analysis? Real-world examples and insights into the art of extracting knowledge from data.
Link to What Is Qualitative Data? Characteristics & Examples What Is Qualitative Data? Characteristics & ExamplesWhat is qualitative data, and why does it matter? Explore its essential characteristics and real-world examples so you can confidently apply it.
Link to What Is Quantitative Data? Characteristics & Examples What Is Quantitative Data? Characteristics & ExamplesQuantitative Data is data that can be measured numerically. Learn more about the types of quantitative data & how it is used.
Link to What is Raw Data? Definition, Examples, & Processing Steps What is Raw Data? Definition, Examples, & Processing StepsRaw data is unprocessed data that has not been organized or analyzed. Learn about raw data, its definition, examples, and processing steps.
Link to 7 Data Analytics Trends 7 Data Analytics TrendsData analytics is an ever-evolving field. Discover the top 7 data analytics trends to watch, from AI-driven analytics to cloud-based solutions.
- AI Link to 9 Best AI Certification Courses to Future-Proof Your Career 9 Best AI Certification Courses to Future-Proof Your Career
Deciding on the best AI certification courses to take? Our 2024 guide details the 9 top courses you need!
Link to 9 Top RPA Companies of 2024: Front Runners in Smart Technology 9 Top RPA Companies of 2024: Front Runners in Smart TechnologyConsidering RPA companies for smarter solutions? Check out 2024's top 9 innovators in business technology today!
Link to AI in Cybersecurity: The Comprehensive Guide to Modern Security AI in Cybersecurity: The Comprehensive Guide to Modern SecurityIs AI in cybersecurity our future defense? Discover how it reshapes threat detection and security strategies.
Link to Coursera: Machine Learning (ML) Courses for Certification in 2024 Coursera: Machine Learning (ML) Courses for Certification in 2024Curious about Coursera machine learning for 2024? Gain cutting-edge skills & certification with comprehensive courses.
Link to Mastering AI Data Classification: Ultimate Guide Mastering AI Data Classification: Ultimate GuideInterested in AI-powered data classification? Elevate your data management with cutting-edge technology!
Link to 100 Top AI Companies Trendsetting In 2024 100 Top AI Companies Trendsetting In 2024Eager to learn about the top 100 AI companies of 2024? Learn about the AI trendsetters of the future.
- Cloud Link to 15 Top Cloud Computing Companies: Get Cloud Service In 2025 15 Top Cloud Computing Companies: Get Cloud Service In 2025
Which cloud computing companies offer superior services? See our list of 2025's top cloud providers.
Link to Top 10 Managed Service Providers (MSPs) for 2025 Top 10 Managed Service Providers (MSPs) for 2025Discover the top managed service providers (MSPs) for 2025. Learn about MSPs and their services and find the best one for your needs.
Link to Common Data Visualization Examples: Transform Numbers into Narratives Common Data Visualization Examples: Transform Numbers into NarrativesWant to see data come to life? Explore data visualization examples that turn abstract numbers into visual stories.
Link to 9 Best AI Certification Courses to Future-Proof Your Career 9 Best AI Certification Courses to Future-Proof Your CareerDeciding on the best AI certification courses to take? Our 2024 guide details the 9 top courses you need!
Link to 10 Best Cloud-Based Project Management Software Platforms of 2024 10 Best Cloud-Based Project Management Software Platforms of 2024Interested in cloud based project management software? Optimize workflow with elite software of 2024.
Link to 76 Top SaaS Companies to Know In 2024 76 Top SaaS Companies to Know In 2024Discover the top software-as-a-service (SaaS) companies. Learn about the latest trends in SaaS and the most successful SaaS companies.
- Applications Link to 8 Best Data Analytics Tools: Gain Data-Driven Advantage 8 Best Data Analytics Tools: Gain Data-Driven Advantage
Seeking data analytics tools to transform your business? Explore 10 strategic picks for advantage in 2024.
Link to Common Data Visualization Examples: Transform Numbers into Narratives Common Data Visualization Examples: Transform Numbers into NarrativesWant to see data come to life? Explore data visualization examples that turn abstract numbers into visual stories.
Link to 10 Best Cloud-Based Project Management Software Platforms of 2024 10 Best Cloud-Based Project Management Software Platforms of 2024Interested in cloud based project management software? Optimize workflow with elite software of 2024.
Link to HubSpot CRM vs. Salesforce: Head-To-Head Comparison (2024) HubSpot CRM vs. Salesforce: Head-To-Head Comparison (2024)Wondering how HubSpot CRM stacks up against Salesforce? Read the head-to-head comparison of 2024.
Link to Top 7 Data Science Tools: Essentials For 2024 Top 7 Data Science Tools: Essentials For 2024Eager to optimize your data science toolkit? Discover the essentials for 2024.
Link to Top 7 Data Analyst Companies Hiring In 2024 Top 7 Data Analyst Companies Hiring In 2024Curious about data analyst companies? Unveil the 7 best places to advance your career in 2024.
- Mobile Link to A Guide to the 12 Most Common IoT Protocols & Standards A Guide to the 12 Most Common IoT Protocols & Standards
What drives IoT protocols and standards? Uncover the answers in our guide, spotlighting the 12 most influential protocols in the IoT domain.
Link to Internet of Things Trends Internet of Things TrendsThis article provides the latest trends on the Internet of Things (IoT). Discover the future of IoT.
Link to The Future of Low Code No Code The Future of Low Code No CodeLow-Code/No-Code (LC/NC) platforms are revolutionizing the software development industry. Today, anyone can use them to create their own app, tool, or
Link to 85 Top IoT Devices 85 Top IoT DevicesInternet of Things (IoT) devices are transforming business. Explore the top 85 IoT devices & those who are investing in the future of IoT.
Link to The Wireless Networking Market The Wireless Networking MarketWhat's the state of the wireless networking market, including its features, benefits, use cases, and providers?
Link to How Wireless Networking is Used by Meraki, Cradlepoint, AOptix, Strix Systems, and Veniam How Wireless Networking is Used by Meraki, Cradlepoint, AOptix, Strix Systems, and VeniamHow are wireless networking technologies being used by companies in different industries?
- Open Source Link to Best Open Source Software List For Data Management In 2024 Best Open Source Software List For Data Management In 2024
Interested in the best open source software? Read our 2024 list for innovative data management solutions.
Link to 34 Top Open Source Software Companies Shaping 2024 34 Top Open Source Software Companies Shaping 2024Exploring open source companies for 2024? Discover the leading firms championing open-source solutions.
Link to Open Source CRMs: 10 Best Open Source Software Solutions for 2024 Open Source CRMs: 10 Best Open Source Software Solutions for 2024Looking for CRM open source software for 2024? Reviewing the 10 best solutions for data management.
Link to What is Data Scraping? Definition & How to Use it What is Data Scraping? Definition & How to Use itData Scraping is a process of collecting data from websites & other sources for further processing. Learn about the definition, process & how to use it.
Link to Open Source Software: Top Sites Open Source Software: Top SitesOpen source software is a type of software that allows anyone to view the code, and then use the code to contribute to or create other projects. Some This list of leading open source software sites is an ultimate resource for open source software users.
Link to Dell Technologies: Enterprise SONiC Distribution Review Dell Technologies: Enterprise SONiC Distribution Review
Dell Technologies: Enterprise SONiC Distribution ReviewWhere does Dell Technologies Enterprise SONiC Distribution stand in the network operating system (NOS) market, including its features & reviews?
- Security Link to AI in Cybersecurity: The Comprehensive Guide to Modern Security AI in Cybersecurity: The Comprehensive Guide to Modern Security
Is AI in cybersecurity our future defense? Discover how it reshapes threat detection and security strategies.
Link to What Is Cybersecurity? Definitions, Practices, Threats What Is Cybersecurity? Definitions, Practices, ThreatsWondering what is cybersecurity? Get a comprehensive overview, expert practices, and insights into cyber threats.
Link to How to Secure a Network: 9 Key Actions to Secure Your Data How to Secure a Network: 9 Key Actions to Secure Your DataQuestioning how to secure a network? Explore 9 key steps for securing your network and safeguarding sensitive data.
Link to 7 Best Data Security Software: Solutions For 2024 7 Best Data Security Software: Solutions For 2024Is your data security software ready for 2024? Explore the 7 best solutions now.
Link to 11 Top Cybersecurity Certifications to Consider In 2024 11 Top Cybersecurity Certifications to Consider In 2024Exploring cybersecurity certifications? Uncover the top 11 certifications that employers truly value in IT security.
Link to Nmap Vulnerability Scan: How To Easily Run And Assess Risk Nmap Vulnerability Scan: How To Easily Run And Assess RiskDiscover how to secure your network with an nmap vulnerability scan. Explore the easy, step-by-step process now.
- Storage Link to 10 Top Storage Certifications for Data Professionals In 2024 10 Top Storage Certifications for Data Professionals In 2024
Looking for storage certifications? Learn about the 10 top certifications for data professionals in 2024.
Link to What is Data Compression & How Does it Work? What is Data Compression & How Does it Work?Data compression is a process used to reduce the amount of data sent over a network. Learn about the algorithms used to compress data and how it works.
Link to What Is a Data Pipeline? Examples & Types What Is a Data Pipeline? Examples & TypesA data pipeline is a set of processes that move data from one system to another. Learn how data pipelines can help you manage and analyze data efficiently.
Link to Top 10 Data Center Certifications Top 10 Data Center CertificationsData center certifications are essential for success in the industry. Here are the top 10 certifications to consider to ensure you are ahead of the curve.
Link to What is a Data Lakehouse? Definition, Benefits and Features What is a Data Lakehouse? Definition, Benefits and FeaturesLearn the definition of a data lakehouse, the benefits of using one, and the features that make it an essential part of a modern data architecture.
Link to Top 5 Current Database Trends Top 5 Current Database TrendsDatabases are undergoing massive change as they transition from on-prem to the cloud. Find out what the main trends are in the database space.
- Networks Networks
- ERP ERP
-
- Careers Careers