


Quality data beats quality algorithms – this simple fact underscores the problem all data scientists know too well. Without high-quality data, their models are effectively useless.
Unfortunately, their colleagues who are tasked with sourcing the data don’t have too many options, and if you asked many of them off the record, they would gladly switch roles with Sisyphus, the figure from Greek mythology, doomed to eternally roll a boulder up a hill only to have it to roll down every time it neared the top.
Legacy suppliers, public resources, and many others approach data with the same mentality, “do you want it, or not?” leaving data scientists with the messy, time-consuming task of cleaning heaps of historical data to uncover the representative sample they need.
Fifty years ago, it would’ve been impossible to predict the value data represents today. Why would anyone have been concerned with database architecture when the societal expectation for progress was the development of flying cars and the establishment of space colonies?
While we aren’t there yet, you’d be hard-pressed to find a company today that would admit to not being data-driven. However, we have amassed 2.7 zettabytes – one sextillion or 1,000,000,000,000,000,000,000 bytes of data in our digital universe most of which is garbage.
A survey of data scientists by machine learning and AI company Figure Eight (formerly known as CrowdFlower) revealed that approximately 80% of a data scientist’s time is spent simply collecting, cleaning, and organizing data. Only 20% of their time is spent on more creative activities like mining data for patterns, refining algorithms, and building training sets.
In other words, for each day spent analyzing data, data scientists spend four days doing data preparation.
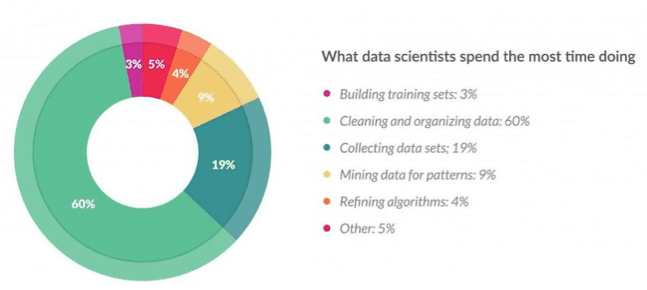
FigureEight (CrowdFlower) Data Science Report
This digital janitor work is by far the most time-consuming part of a data scientist’s job. While it’s certainly an important aspect of the job, you can’t trust the outputs of messy data hence the cleansing process. However, This process prevents data scientists from spending more of their time on higher-value activities that have a direct impact on their company’s operations and strategy.
Therein lies the challenge: How do we decrease the amount of time spent on data wrangling in order to increase the amount of time spent on value-generating activities?
The solution is schema standardization enforced by a third party.
Although data is widely considered to be highly complex by the general population, those in the industry know data ultimately consists of two components: names and types.
Names and types comprise the schema of any given data set. When data scientists build models for analysis, they are often incorporating multiple raw data sets from various sources. Each of these data sources uses their own schema, which results in a vast array of incompatible names and types. Before they can get to the fun part, data scientists must standardize these attributes across each source to produce a representative sample or compatible data set. On the one hand, this process prevents garbage in, garbage out, and on the other, unfortunately, it absorbs 80% of the workweek for data scientists.
When data sources adhere to schema standardization, however, names and types are innately compatible meaning all data sets work together from the beginning. Data from multiple sources can be normalized into a single feed and record level provenance by source can now be retained. Rather than spending the bulk of their time collecting and cleaning, data scientists can skip this step and go to data transformation, mining, and/or modeling. Schema standardization eliminates the time needed for data scientists to reformat and match the data so a majority of their time can now be spent on value-generating activities.
By leveraging a third-party offering that enforces schema standardization, and the ability to transform data in-house, data scientists can win back hundreds of hours of productivity, reduce costs associated with errors, and most importantly, help their organization make well-informed decisions.
About the Author:
By Nathan Dolan, Technical, Partner Success Associate, Narrative
Huawei’s AI Update: Things Are Moving Faster Than We Think
FEATURE | By Rob Enderle,
December 04, 2020
Keeping Machine Learning Algorithms Honest in the ‘Ethics-First’ Era
ARTIFICIAL INTELLIGENCE | By Guest Author,
November 18, 2020
Key Trends in Chatbots and RPA
FEATURE | By Guest Author,
November 10, 2020
FEATURE | By Samuel Greengard,
November 05, 2020
ARTIFICIAL INTELLIGENCE | By Guest Author,
November 02, 2020
How Intel’s Work With Autonomous Cars Could Redefine General Purpose AI
ARTIFICIAL INTELLIGENCE | By Rob Enderle,
October 29, 2020
Dell Technologies World: Weaving Together Human And Machine Interaction For AI And Robotics
ARTIFICIAL INTELLIGENCE | By Rob Enderle,
October 23, 2020
The Super Moderator, or How IBM Project Debater Could Save Social Media
FEATURE | By Rob Enderle,
October 16, 2020
FEATURE | By Cynthia Harvey,
October 07, 2020
ARTIFICIAL INTELLIGENCE | By Guest Author,
October 05, 2020
CIOs Discuss the Promise of AI and Data Science
FEATURE | By Guest Author,
September 25, 2020
Microsoft Is Building An AI Product That Could Predict The Future
FEATURE | By Rob Enderle,
September 25, 2020
Top 10 Machine Learning Companies 2020
FEATURE | By Cynthia Harvey,
September 22, 2020
NVIDIA and ARM: Massively Changing The AI Landscape
ARTIFICIAL INTELLIGENCE | By Rob Enderle,
September 18, 2020
Continuous Intelligence: Expert Discussion [Video and Podcast]
ARTIFICIAL INTELLIGENCE | By James Maguire,
September 14, 2020
Artificial Intelligence: Governance and Ethics [Video]
ARTIFICIAL INTELLIGENCE | By James Maguire,
September 13, 2020
IBM Watson At The US Open: Showcasing The Power Of A Mature Enterprise-Class AI
FEATURE | By Rob Enderle,
September 11, 2020
Artificial Intelligence: Perception vs. Reality
FEATURE | By James Maguire,
September 09, 2020
Anticipating The Coming Wave Of AI Enhanced PCs
FEATURE | By Rob Enderle,
September 05, 2020
The Critical Nature Of IBM’s NLP (Natural Language Processing) Effort
ARTIFICIAL INTELLIGENCE | By Rob Enderle,
August 14, 2020

Datamation is the leading industry resource for B2B data professionals and technology buyers. Datamation's focus is on providing insight into the latest trends and innovation in AI, data security, big data, and more, along with in-depth product recommendations and comparisons. More than 1.7M users gain insight and guidance from Datamation every year.
Advertise with TechnologyAdvice on Datamation and our other data and technology-focused platforms.
Advertise with Us







Property of TechnologyAdvice.
© 2025 TechnologyAdvice. All Rights Reserved
Advertiser Disclosure: Some of the products that appear on this
site are from companies from which TechnologyAdvice receives
compensation. This compensation may impact how and where products
appear on this site including, for example, the order in which
they appear. TechnologyAdvice does not include all companies
or all types of products available in the marketplace.


